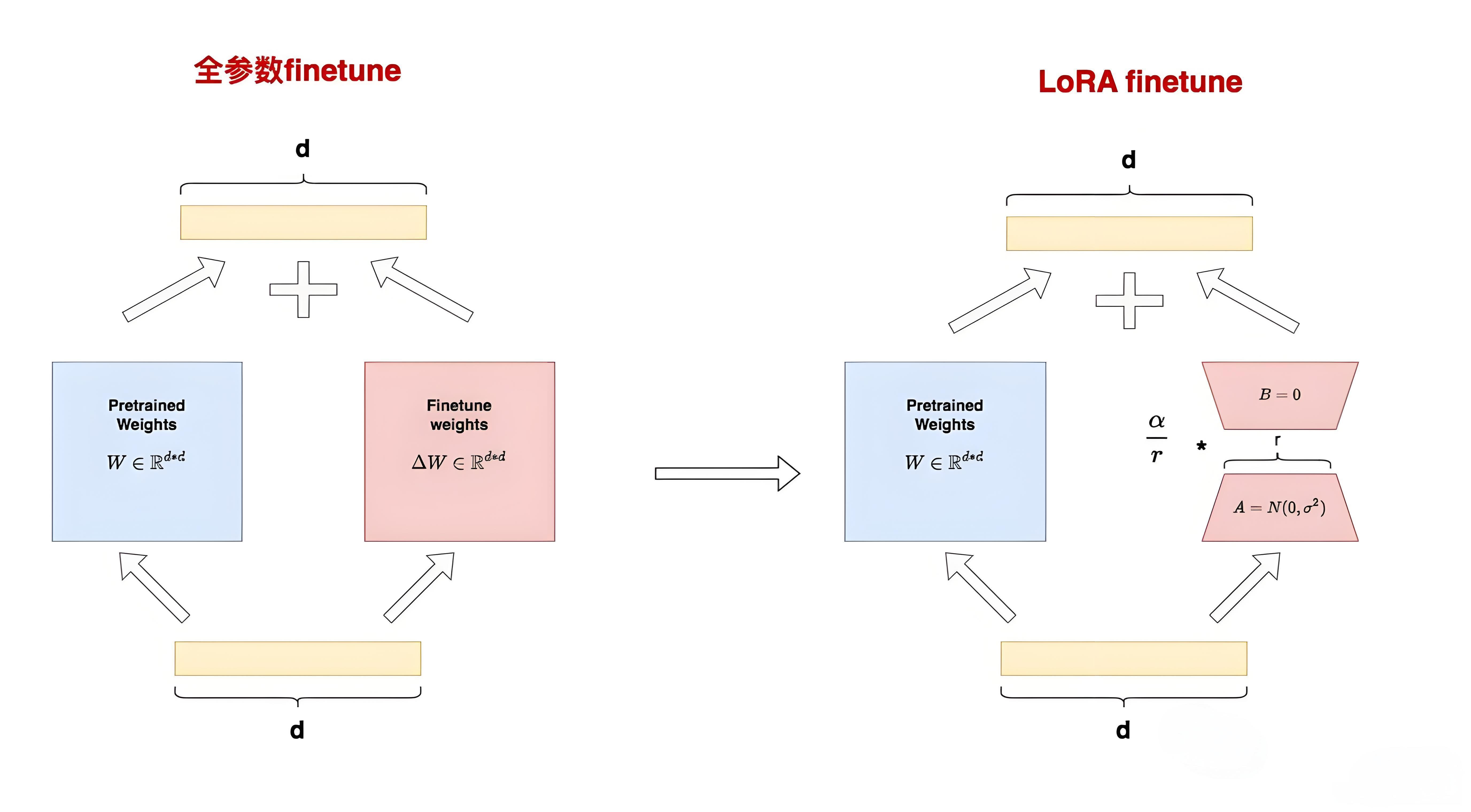
LoRA
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.A = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)
class LinearWithLoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
lora = self.lora.A @ self.lora.B # Combine LoRA matrices
# Then combine LoRA with orig. weights
combined_weight = self.linear.weight + self.lora.alpha*lora.T
return F.linear(x, combined_weight, self.linear.bias)
DoRA
class LinearWithDoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
self.m = nn.Parameter(
self.linear.weight.norm(p=2, dim=0, keepdim=True))
# Code loosely inspired by
# https://github.com/catid/dora/blob/main/dora.py
def forward(self, x):
lora = self.lora.A @ self.lora.B
numerator = self.linear.weight + self.lora.alpha*lora.T
denominator = numerator.norm(p=2, dim=0, keepdim=True)
directional_component = numerator / denominator
new_weight = self.m * directional_component
return F.linear(x, new_weight, self.linear.bias)
LoRA. py
import torch
import torch.nn as nn
import torch.nn.functional as F
import copy
from typing import List
class LoraLinear(nn.Module):
def __init__(
self,
base_layer: nn.Linear, # 原来的线性层
r: int = 8, # lora rank
alpha: int = 16, # lora alpha
test_mode: bool = False, # 测试模式,用于控制 lora_B 是否为全零
):
super(LoraLinear, self).__init__()
self.base_layer = copy.deepcopy(base_layer)
self.r = r
self.alpha = alpha
self.__attach = True
# 定义 lora_A 和 lora_B 为 Parameter
self.lora_A = nn.Parameter(torch.empty((base_layer.in_features, r), dtype=base_layer.weight.dtype)).to(base_layer.weight.device)
self.lora_B = nn.Parameter(torch.empty((r, base_layer.out_features), dtype=base_layer.weight.dtype)).to(base_layer.weight.device)
# 初始化 lora 矩阵
nn.init.normal_(self.lora_A, mean=0.0, std=0.02)
if test_mode:
nn.init.normal_(self.lora_B, mean=0.0, std=0.02)
else:
nn.init.constant_(self.lora_B, 10)
# nn.init.zeros_(self.lora_B)
# 冻结原来的层的参数
for param in self.base_layer.parameters():
param.requires_grad = False
@property
def weight(self):
if self.__attach:
scaling = float(self.alpha) / float(self.r) # lora 缩放系数
lora_weight = self.lora_A.float()@self.lora_B.float()
return self.base_layer.weight + lora_weight.half().T*scaling
else:
return self.base_layer.weight
@property
def bias(self):
return self.base_layer.bias
def set_attach_mode(self, attach: bool):
self.__attach = attach
def forward(self, x: torch.Tensor) -> torch.Tensor:
# lora_adjustment = F.linear(self.dropout(x), self.lora_A)
# lora_adjustment = F.linear(lora_adjustment, self.lora_B)
return F.linear(x, self.weight, self.bias)
def replace_linear_with_lora(
module: nn.Module,
r: int = 8,
alpha: int = 16,
# dropout_p: float = 0.0,
embed_requires_grad: bool = False, # embedding 层是否训练
norm_requires_grad: bool = False, # norm 层是否训练
head_requires_grad: bool = False, # lm_head 层是否训练(Causal LM才有)
test_mode: bool = False, # 测试模式,用于控制 lora_B 是否为全零
):
"""
找到 module 中所有线性层并递归替换
"""
for name, child in module.named_children():
# 先处理额外的层,lm_head 也是 linear,所以先处理
if any(s in name for s in ['embed', 'norm', 'lm_head']):
requires_grad = embed_requires_grad if 'embed' in name \
else norm_requires_grad if 'norm' in name \
else head_requires_grad
for param in child.parameters():
param.requires_grad = requires_grad
# 替换所有线性层,QLoRA 做法
elif isinstance(child, nn.Linear):
lora_linear = LoraLinear(child, r=r, alpha=alpha, test_mode=test_mode)
setattr(module, name, lora_linear)
# 递归向下替换
else:
replace_linear_with_lora(
child, r, alpha,
embed_requires_grad, norm_requires_grad, head_requires_grad,
test_mode=test_mode
)
def unload_lora(module: nn.Module, adapter_name: str = 'adapter'):
"""
卸载 lora 参数,并将原模型恢复至加载 lora 前的样子
"""
lora_parameters = {}
def search_lora_linear(module: nn.Module, prefix: List[str]):
for name, child in module.named_children():
new_prefix = prefix + [name]
if isinstance(child, LoraLinear):
# 保存 lora 参数
lora_parameters['.'.join(new_prefix)] = {
"lora_A_weight": child.lora_A.data.cpu(),
"lora_B_weight": child.lora_B.data.cpu(),
"r": child.r,
"alpha": child.alpha,
"dropout_p": child.dropout.p,
}
setattr(module, name, child.base_layer)
else:
search_lora_linear(child, new_prefix)
search_lora_linear(module, [])
# 解冻原模型
for name, param in module.named_parameters():
param.requires_grad = True
torch.save(lora_parameters, f"{adapter_name}.pt")
def load_lora(module: nn.Module, adapter_name: str = 'adapter'):
"""
加载 lora 参数
"""
lora_parameters = torch.load(f"{adapter_name}.pt")
for name, lora_params in lora_parameters.items():
child = dict(module.named_modules())[name]
if isinstance(child, nn.Linear):
lora_linear = LoraLinear(child, lora_params['r'], lora_params['alpha'], lora_params['dropout_p'])
lora_linear.lora_A.data = lora_params["lora_A_weight"].to(lora_linear.lora_A.device)
lora_linear.lora_B.data = lora_params["lora_B_weight"].to(lora_linear.lora_B.device)
# 名称示例:layers.0.self_attn.q_proj
# 根据名称循环找到所需 module
parts = name.split(".")
obj = module
for part in parts[:-1]: # 不包括最后一级
obj = getattr(obj, part)
setattr(obj, parts[-1], lora_linear)
# 恢复原来的冻结方式,这里简单地除了 lora 全冻结
for name, param in module.named_parameters():
if any(s in name for s in ['embed', 'norm', 'lm_head']):
param.requires_grad = False
def attach_lora(model_with_lora: nn.Module, attach: bool):
def search_lora_linear(module: nn.Module, prefix: List[str]):
for name, child in module.named_children():
new_prefix = prefix + [name]
if isinstance(child, LoraLinear):
child.set_attach_mode(attach=attach)
else:
search_lora_linear(child, new_prefix)
search_lora_linear(model_with_lora, [])