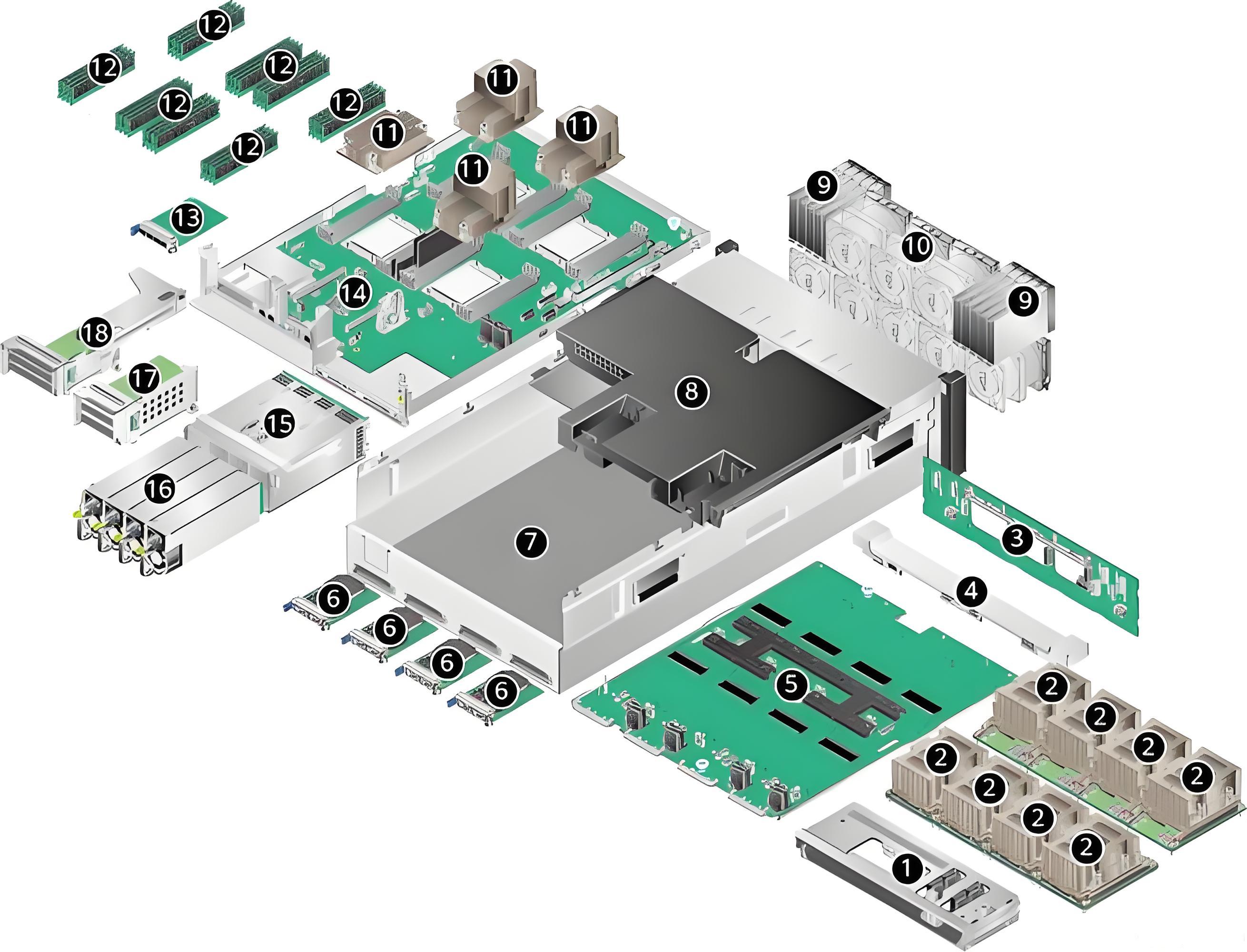
配置
华为 Atlas 800I A2推理服务器完整硬件配置表
核心硬件配置
| 模块 | 配置参数 |
|---|---|
| 处理器 | 4*鲲鹏920处理器(7265/5250型号),双路 Hydra 总线互连(30GT/s),集成 PCIe 4.0控制器 |
| 内存 | (512GB)32个 DDR4插槽,最高支持3200 MT/s,单条容量16/32/64GB |
| NPU 配置 | - 型号:昇腾910B3 AI 处理器 - 数量:8个 NPU 模组全互联架构 - 运行内存:单卡64GB/整机512GB - 单卡性能:FP16算力280 TFLOPS - 互联带宽:整机392GB/s |
| 存储配置 | - 选项1:82.5英寸 SATA(槽位0-7)+22.5英寸 NVMe(槽位8-9) - 选项2:42.5英寸 SATA(槽位0-1、4-5)+62.5英寸 NVMe(槽位2-3、6-9) (SP686C RAID 卡支持 SATA/NVMe 混合使用) |
| 网络接口 | - 参数面:8200GE QSFP 接口(RoCE 协议) - 存储面/业务面:各225GE - 管理面:1*1GE - PCIe 互联:NPU 与 CPU 通过 PCIe 4.0 x16互联(总带宽512GB/s) |
物理与扩展特性
| 模块 | 配置参数 |
|---|---|
| PCIe 扩展 | - 存储配置选项1支持3个 PCIe 4.0插槽 - 选项2支持2个 PCIe 4.0插槽 |
| 电源与散热 | 4个热插拔2.6kW 电源(2+2冗余) 8个热插拔风扇(N+1冗余) |
| 物理规格 | 4U 机架式(175mm×447mm×790mm),净重70kg |
| 工作环境 | 温度5℃~35℃ |
关键功能说明
- NPU 逻辑映射:iBMC 显示 NPU1
8对应 npu-smi 工具的 NPU07,需注意物理位置与逻辑 ID 匹配 - 容器支持:通过 npu-smi 工具动态分配 AI CPU 和算力资源,支持物理机/虚拟机/容器化部署
- RAID 兼容性:仅 SP686C RAID 卡支持 SATA/NVMe 混合使用,其他 RAID 卡仅支持 NVMe 硬盘
- 视频处理能力:支持1080P 视频解码480FPS,JPEG 解码最大分辨率16384x16384
注意:昇腾910b3不支持容器共享技术
mindie 部署
docker-compose. yml
services:
mindie:
container_name: mindie
image: llama3.1:8bv1 # 原始镜像:swr.cn-central-221.ovaijisuan.com/wh-aicc-fae/mindie:910B-ascend_24.1.rc3-cann_8.0.rc3.beta1-py_3.10-ubuntu_20.04-aarch64-mindie_1.0.RC3.04
privileged: true
networks:
- docker_default
volumes:
- /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro
- /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/:ro
- /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi:ro
- /usr/local/sbin/:/usr/local/sbin/:ro
- /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf:ro
- /var/log/npu/slog/:/var/log/npu/slog:ro
- /var/log/npu/profiling/:/var/log/npu/profiling:ro
- /var/log/npu/dump/:/var/log/npu/dump:ro
- /var/log/npu/:/usr/slog:ro
- /share-storage/llmfinetuning/ms_cache:/root/.cache/modelscope
- /share-storage/mindie/home/Meta-Llama-3.1-8B-Instruct:/home/model/Meta-Llama-3.1-8B-Instruct
- /share-storage/mindie/home/law_sft:/home/model/law_sft
- /share-storage/mindie/home/config.json:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json
# - /share-storage/mindie/home/start.sh:/home/start.sh # 添加 start.sh 文件映射
expose:
- 1025
ports:
- 1025:1025
ipc: host
tty: true
shm_size: '16gb'
# command: bash /home/start.sh # 修改启动脚本为 start.sh
devices:
- /dev/davinci1
- /dev/davinci2
- /dev/davinci_manager
- /dev/devmm_svm
- /dev/hisi_hdc
restart: unless-stopped
networks:
docker_default:
external: true
config. json
{
"Version" : "1.0.0",
"LogConfig" :
{
"logLevel" : "Info",
"logFileSize" : 20,
"logFileNum" : 20,
"logPath" : "logs/mindservice.log"
},
"ServerConfig" :
{
"ipAddress" : "172.26.0.10", // 只能填写ip地址,0.0.0.0无效
"managementIpAddress" : "127.0.0.2",
"port" : 1025,
"managementPort" : 1026,
"metricsPort" : 1027,
"allowAllZeroIpListening" : false,
"maxLinkNum" : 1000,
"httpsEnabled" : false,
"fullTextEnabled" : false,
"tlsCaPath" : "security/ca/",
"tlsCaFile" : ["ca.pem"],
"tlsCert" : "security/certs/server.pem",
"tlsPk" : "security/keys/server.key.pem",
"tlsPkPwd" : "security/pass/key_pwd.txt",
"tlsCrl" : "security/certs/server_crl.pem",
"managementTlsCaFile" : ["management_ca.pem"],
"managementTlsCert" : "security/certs/management/server.pem",
"managementTlsPk" : "security/keys/management/server.key.pem",
"managementTlsPkPwd" : "security/pass/management/key_pwd.txt",
"managementTlsCrl" : "security/certs/management/server_crl.pem",
"kmcKsfMaster" : "tools/pmt/master/ksfa",
"kmcKsfStandby" : "tools/pmt/standby/ksfb",
"inferMode" : "standard",
"interCommTLSEnabled" : false,
"interCommPort" : 1121,
"interCommTlsCaFile" : "security/grpc/ca/ca.pem",
"interCommTlsCert" : "security/grpc/certs/server.pem",
"interCommPk" : "security/grpc/keys/server.key.pem",
"interCommPkPwd" : "security/grpc/pass/key_pwd.txt",
"interCommTlsCrl" : "security/certs/server_crl.pem",
"openAiSupport" : "vllm"
},
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 1, // 服务实例个数,对应下一行第一层的个数
"npuDeviceIds" : [[1,2]], // 第一层表示实例,第二层表示每个实例GPU的个数
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : false,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : true,
"interNodeTlsCaFile" : "security/grpc/ca/ca.pem",
"interNodeTlsCert" : "security/grpc/certs/server.pem",
"interNodeTlsPk" : "security/grpc/keys/server.key.pem",
"interNodeTlsPkPwd" : "security/grpc/pass/mindie_server_key_pwd.txt",
"interNodeTlsCrl" : "security/grpc/certs/server_crl.pem",
"interNodeKmcKsfMaster" : "tools/pmt/master/ksfa",
"interNodeKmcKsfStandby" : "tools/pmt/standby/ksfb",
"ModelDeployConfig" :
{
"maxSeqLen" : 131072, // 最大序列长度
"maxInputTokenLen" : 131072, // 输入的最大序列长度
"truncation" : false, // true表示超过输入最大序列长度,则按照一定的规则进行截取。
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "llama3.1_8b",
"modelWeightPath" : "/home/model/law_sft/",
"worldSize" : 2, // 一个实例所拥有的NPU数量
"cpuMemSize" : 64,
"npuMemSize" : -1,
"backendType" : "atb"
}
]
},
"ScheduleConfig" :
{
"templateType" : "Standard",
"templateName" : "Standard_LLM",
"cacheBlockSize" : 128,
"maxPrefillBatchSize" : 50,
"maxPrefillTokens" : 131072, // 如果显存不够,降低这个参数可以降低显存。
"prefillTimeMsPerReq" : 150,
"prefillPolicyType" : 0,
"decodeTimeMsPerReq" : 50,
"decodePolicyType" : 0,
"maxBatchSize" : 200,
"maxIterTimes" : 512,
"maxPreemptCount" : 0,
"supportSelectBatch" : false,
"maxQueueDelayMicroseconds" : 5000
}
}
}
启动
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/mindie/set_env.sh
nohup /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon &
text-embeding-inference 部署
docker-compose. yml
services:
bge-m3:
container_name: bge-m3
image: swr.cn-south-1.myhuaweicloud.com/ascendhub/mis-tei:6.0.RC3-800I-A2-aarch64
entrypoint: /home/HwHiAiUser/start.sh
command:
- "BAAI/bge-m3"
- "0.0.0.0"
- "8080"
networks:
- docker_default
volumes:
- /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro
- /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/:ro
- /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi:ro
- /usr/local/sbin/:/usr/local/sbin/:ro
- /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf:ro
- /var/log/npu/slog/:/var/log/npu/slog:ro
- /var/log/npu/profiling/:/var/log/npu/profiling:ro
- /var/log/npu/dump/:/var/log/npu/dump:ro
- /var/log/npu/:/usr/slog:ro
- /share-storage/mindie/model:/home/HwHiAiUser/model
expose:
- 8080
- 9090
ipc: host
tty: true
shm_size: '16gb'
# stdin_open: true
# command: lmdeploy serve api_server --backend pytorch --device ascend --eager-mode --chat-template llama3_1 ./sftmodels/identity
environment:
- ASCEND_VISIBLE_DEVICES=1
devices:
- /dev/davinci0
# - /dev/davinci1
# - /dev/davinci2
# - /dev/davinci3
# - /dev/davinci4
# - /dev/davinci5
# - /dev/davinci6
# - /dev/davinci7
- /dev/davinci_manager
- /dev/devmm_svm
- /dev/hisi_hdc
restart: unless-stopped
networks:
docker_default:
external: true
启动指令
/home/HwHiAiUser/start.sh BAAI/bge-m3 0.0.0.0 8080
/home/HwHiAiUser/start.sh BAAI/bge-reranker-v2-m3 0.0.0.0 9090
lmdeploy+nginx 负载均衡
docker-compose. yml
services:
lmdeploy-1:
container_name: lmdeploy-1
image: lmdeploy-aarch64-ascend:latest
networks:
- docker_default
volumes:
- /share-storage/llmfinetuning/output:/opt/lmdeploy/sftmodels:ro
- /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro
- /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/:ro
- /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi:ro
- /usr/local/sbin/:/usr/local/sbin/:ro
- /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf:ro
- /var/log/npu/slog/:/var/log/npu/slog:ro
- /var/log/npu/profiling/:/var/log/npu/profiling:ro
- /var/log/npu/dump/:/var/log/npu/dump:ro
- /var/log/npu/:/usr/slog:ro
expose:
- 23333
ipc: host
tty: true
shm_size: '16gb'
# stdin_open: true
# working_dir: /opt/lmdeploy
# environment:
# - ASCEND_VISIBLE_DEVICES=2
# entrypoint: lmdeploy
# command:
# - "serve"
# - "api_server"
# - "--backend"
# - "pytorch"
# - "--device"
# - "ascend"
# - "--eager-mode"
# - "--model-name"
# - "llama3_1_8b"
# - "--chat-template"
# - "llama3_1"
# - "./sftmodels/Meta-Llama-3.1-8B-Instruct"
# command: lmdeploy serve api_server --backend pytorch --device ascend --eager-mode --chat-template llama3_1 ./sftmodels/identity
devices:
# - /dev/davinci0
# - /dev/davinci1
- /dev/davinci2
# - /dev/davinci3
# - /dev/davinci4
# - /dev/davinci5
# - /dev/davinci6
# - /dev/davinci7
- /dev/davinci_manager
- /dev/devmm_svm
- /dev/hisi_hdc
restart: unless-stopped
lmdeploy-2:
container_name: lmdeploy-2
image: lmdeploy-aarch64-ascend:latest
networks:
- docker_default
volumes:
- /share-storage/llmfinetuning/output:/opt/lmdeploy/sftmodels:ro
- /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro
- /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/:ro
- /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi:ro
- /usr/local/sbin/:/usr/local/sbin/:ro
- /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf:ro
- /var/log/npu/slog/:/var/log/npu/slog:ro
- /var/log/npu/profiling/:/var/log/npu/profiling:ro
- /var/log/npu/dump/:/var/log/npu/dump:ro
- /var/log/npu/:/usr/slog:ro
expose:
- 23333
ipc: host
tty: true
shm_size: '16gb'
# stdin_open: true
working_dir: /opt/lmdeploy
# environment:
# - ASCEND_VISIBLE_DEVICES=3
# entrypoint: lmdeploy
# command:
# - "serve"
# - "api_server"
# - "--backend"
# - "pytorch"
# - "--device"
# - "ascend"
# - "--eager-mode"
# - "--model-name"
# - "llama3_1_8b"
# - "--chat-template"
# - "llama3_1"
# - "./sftmodels/Meta-Llama-3.1-8B-Instruct"
# command: lmdeploy serve api_server --backend pytorch --device ascend --eager-mode --chat-template llama3_1 ./sftmodels/identity
devices:
# - /dev/davinci0
# - /dev/davinci1
# - /dev/davinci2
- /dev/davinci3
# - /dev/davinci4
# - /dev/davinci5
# - /dev/davinci6
# - /dev/davinci7
- /dev/davinci_manager
- /dev/devmm_svm
- /dev/hisi_hdc
restart: unless-stopped
ngixn:
image: nginx:latest
container_name: lmdeploy-nginx
networks:
- docker_default
volumes:
- /share-storage/lmdeploy_nginx/nginx.conf:/etc/nginx/nginx.conf:ro
- /share-storage/lmdeploy_nginx/datasets:/datasets:ro
ports:
- "23333:23333"
- "23334:23334"
networks:
docker_default:
external: true
nginx. conf
user nginx;
events {
worker_connections 1000;
}
http {
# 显示目录
# autoindex on;
# 显示文件大小
# autoindex_exact_size on;
# 显示文件时间
# autoindex_localtime on;
upstream lmdeploy {
#ip_hash;
server lmdeploy-1:23333;
server lmdeploy-2:23333;
# server lmdeploy-3:23333;
}
server {
listen 23333;
location / {
proxy_buffering off;
proxy_pass http://lmdeploy/;
}
}
server {
listen 23334;
# 避免中文乱码
charset utf-8;
location / {
root /datasets;
sendfile on;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
}
}
}
启动
lmdeploy serve api_server --backend pytorch --device ascend --eager-mode --chat-template llama3_1 ./sftmodels/identity